Hosting, KI und Solr Wie wir KI-Bots aus Solr aussperren
Bei diversen Kund*innen setzen wir auf Apache Solr für die Webseitensuche. Sobald man etwas höhere Ansprüche hat, wie etwa eigene Datensätze mit Facetten zu durchsuchen oder eine Vorschlagssuche, hat man damit viele Möglichkeiten und Freiheiten, die die TYPO3-eigene indexed_search schlichtweg nicht bietet.
Die Solr-Suche ist aber nicht nur für reguläre Benutzer*innen interessant: Wir nehmen verstärkt wahr, dass Bots die Solr-Ergebnisseiten benutzen, um beispielsweise Trainingsdaten für KI zu sammeln oder Anfragen von Benutzer*innen zu erfüllen. Unser Systemadministrator Alex behält die Leistungskurven der Server im Auge und hat das Team auf den Anstieg hingewiesen:
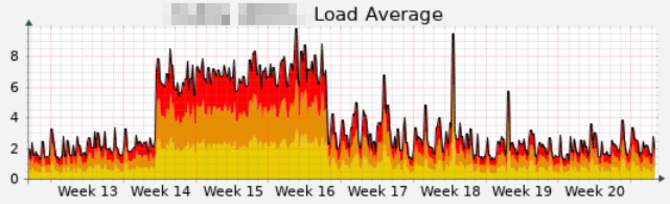
Man kann deutlich erkennen, dass der Server plötzlich sehr viel beschäftigter ist. Das Phänomen beobachten nicht nur wir, auch dkd (die Entwickler der TYPO3-Solr-Extension) haben einen Blogpost zu dem Thema verfasst.
Was ist da los? Ein Blick ins Access-Log macht das Problem etwas klarer. Dieses füllt sich rasant mit Einträgen wie folgenden:
"GET /suchergebnisse/?tx_solr%5Bpage%5D=1&tx_solr%5Bq%5D=Carbon%20Management HTTP/1.1" 200 26448 "-" "python-requests/2.32.5"
"GET /suchergebnisse/?tx_solr%5Bq%5D=Planungsgruppe HTTP/1.1" 200 27161 "-" "-"
"GET /suchergebnisse/?tx_solr%5Bq%5D=Vertriebsassistent+ HTTP/1.1" 200 28964 "-" "Google"
"GET /suchergebnis/?L=0&q=Betriebsordnung&tx_solr%5Bsort%5D=date%20desc HTTP/2.0" 404 224120 "-" "meta-externalagent/1.1 (+https://developers.facebook.com/docs/sharing/webmasters/crawler)"
Es kommen sehr viele Anfragen von unterschiedlichsten IP-Adressen, alle ohne referer, direkt mit einer Suchanfrage. Die Anfragen auf normale Artikel der Website gehen in diesen Suchergebnis-Aufrufen komplett unter. Außerdem werden Ergebnisseiten mit verschiedenen Parameter-Kombinationen durchiteriert. Menschlicher Such-Traffic sieht anders aus, man kann hier also davon ausgehen, dass es sich um Bots handelt.
Professionelle Crawler geben immerhin einen User-Agent an, und bestenfalls auch einen Link mit Hintergrundinformationen. Viele behaupten aber auch einfach, sie seien zum Beispiel ein regulärer Chrome-Browser.
Um Bot-Anfragen auf bestimmte Bereiche der Website zu regulieren, ist der Vorschlag üblicherweise:
By configuring the robots.txt file on your website, you can specify to the Meta web crawlers how you would prefer them to interact with your site. In order to block these crawlers, add a disallow for the relevant crawler to robots.txt
Natürlich haben wir die robots.txt bereits entsprechend konfiguriert, denn Bots haben in der Suchfunktion generell nichts verloren. Diese Einstellung hilft aber offensichtlich nicht, viele Bots halten sich nicht an diese Vorgaben.
Woher kommen die Anfragen? Ich habe mal an einem Abend IP-Adressen aus den Logs zusammengetragen, die die Solr-Suche um 4 Uhr Nachts benutzt haben. Ergebnis: etwa 31.000 unterschiedliche IP-Adressen. Mit manuellem Sperren kommt man hier also nicht weit, zumal das nur reaktiv passieren kann, wenn die Anfragenflut den Server schon in die Knie zwingt.
DDoS ist nicht gleich DDoS
Das klingt nach viel, ist aber ironischerweise nicht genug. Wenn Hosting-Anbieter mit "DDoS-Schutz" oder "KI-gestützter DDoS-Erkennung" werben, dann meinen sie üblicherweise nur die Netzwerkebene. "Oh ja", sagt der Support dann, "Ihr Server ist erreichbar. Nur ist Ihre Anwendung zu langsam". Toll. Danke für nichts.
Das Netzwerk kann all diese Anfragen problemlos ab - trotzdem bekommt niemand mehr die Webseite zu sehen, weil der Server zu lange zum Abarbeiten der Anfragen braucht. Empfohlen wird dann oft Cloudflare mit dem kostenlosen Tarif zu verwenden. Das ist insofern eine Lösung, als dass die Anfragen dann nicht mehr unmittelbar auf den Server einprasseln, sondern zunächst über Cloudflare geleitet werden. Nur die Anfragen, die Cloudflare für legitim hält, gehen schließlich an den Webserver. Könnte man machen, aber das Datenschutzproblem mit einem amerikanischen Dienstleister muss man sich nicht unbedingt ans Bein binden — ganz abgesehen von den Kosten, wenn der kostenlose Tarif nicht mehr ausreicht.
Niemand rechnet mit Javascript
Auch bei der TYPO3-Association sind schon Maßnahmen gegen Bot-Zugriffe im Einsatz. Wenn man z.B. extensions.typo3.org aufruft, blitzt diese Gestalt kurz auf:
Dieses Maskottchen gehört zu Anubis, einem Proxy-Dienst, der vor der Ausgabe der eigentlichen Webseite mittels Javascript den Webbrowser eine kleine Berechnung durchführen lässt (sog. Proof-of-Work). Wer diese Rechenzeit investiert, wird durchgeleitet und Bots tun das in der Regel nicht.
Problematisch ist hier jedoch, dass der ganze Webauftritt dann auch nicht mehr für legitime Bots zugänglich ist, also beispielsweise die Crawler der Google-Suche. Natürlich lassen sich Ausnahmen konfigurieren, aber genauso natürlich könnten sich "bösartige" Bots als legitime ausgeben.
Anstatt also einen vorgeschalteten Dienstleister oder eine zusätzliche Anwendung zu benutzen, lösen wir das Problem in TYPO3:
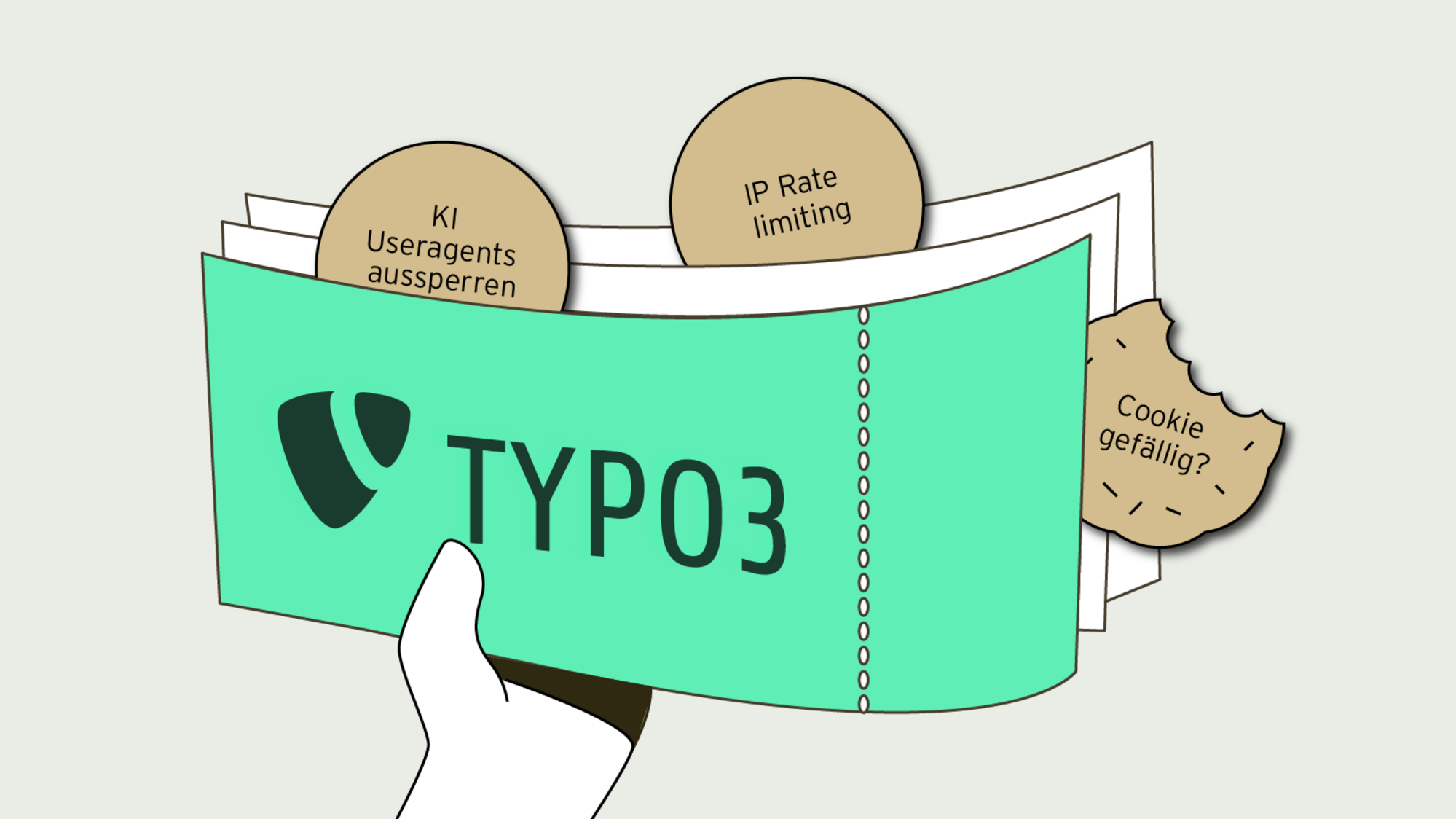
Bitte lösen Sie ein Ticket!
Unsere Lösung ist eine TYPO3-Middleware. Anhand der aufgerufenen URL wird zunächst geschaut, ob die Middleware überhaupt aktiv werden soll. Prinzipiell werden nur Anfragen beachtet, die die Suchfunktion benutzen wollen, also einen URL-Parameter mitbringen, der tx_solr enthält. Ist dies der Fall, haben wir mehrere Filterebenenen, um legitime von unerwünschten Anfragen zu unterscheiden:
1. Bekannte KI User-Agents aussperren
Es gibt bereits Sammlungen von KI User-Agents, auf die man zurückgreifen kann. Der Abgleich in PHP ist schnell (im Sinne von performant). Der User-Agent kann aber frei vergeben werden, ein Bot kann sich also problemlos auch als Chrome oder einen Suchmaschinen-Crawler ausgeben. Daher ist dieses Kriterium nicht ausreichend.
2. IP Rate Limiting
Rate Limiting bedeutet, dass ein einzelner Client innerhalb eines vorgegebenen Zeitraums nur eine bestimmte Anzahl von Anfragen stellen kann. TYPO3 bringt dafür bereits den Symfony Rate Limiter mit, um den Backend-Login gegen Angriffe abzusichern. Der ist leicht zu konfigurieren und verwendet nur ein paar kB auf dem Dateisystem, um sich zeitweise IP-Adressen zu merken. Die Limits haben wir erst mal auf 10 Suchanfragen in einer Minute oder 30 in einer Stunde angesetzt. Probier mal aus, wie viel das tatsächlich ist, das sollte keine menschlichen Benutzer*innen einschränken. Und falls doch: Es gibt dafür eine redaktionelle Fehlerseite. Bei derart vielen verschiedenen IP-Adressen stößt aber auch das Rate Limiting schnell an seine Grenzen, die genannten Limits gelten schließlich für jede Adresse separat.
3. Cookie gefällig?
Die effektivste Methode ist daher fast die einfachste. Normale Benutzer*innen steigen ja nicht auf einer Suchergebnisseite ein, sondern kommen auf die Startseite oder eine Artikelseite. Falls also eine Anfrage nicht auf die Suche geht, schicken wir einen Cookie mit zurück. Sie lösen damit im Hintergrund quasi eine Eintrittskarte für die Suchfunktion. Wird nun eine Suche ausgefüllt, prüft unsere Middleware, ob dieses Cookie vorhanden ist, und liefert nur dann die Ergebnisseite aus. Bots halten sich nicht mit Cookies auf, sie rufen stumpf die Suchergebnisse mit verschiedenen Suchfacetten-Kombinationen auf, und können so effektiv ausgesperrt werden. Da auf diese Weise die Erreichbarkeit der Website enorm verbessert wird, ist es nicht schwer, dieses Cookie als "technisch notwendig" bzw. "legitimes Interesse" zu klassifizieren, wodurch es nicht einwilligungspflichtig ist.
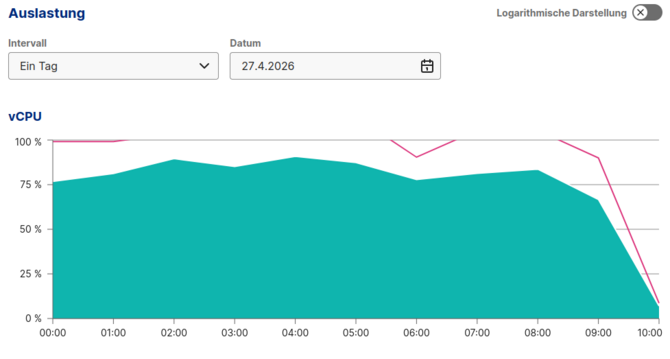
Middleware um 9:30 Uhr deployt
Von 75% Auslastung auf 10% ohne Verkomplizierung des Projekts durch Cloudflare oder Anubis. Da die Middleware auch nur bei Suchanfragen aktiv wird, können legitime Crawler weiterhin das Angebot indexieren, ohne dass eine Gefahr für SEO entsteht.
Vermutlich wird der Wissensdurst der KI-Bots so schnell nicht versiegen. Wir müssen ihn nur so filtern, dass ich meinen Schönheitsschlaf nicht verpasse.